Theoretical Framework
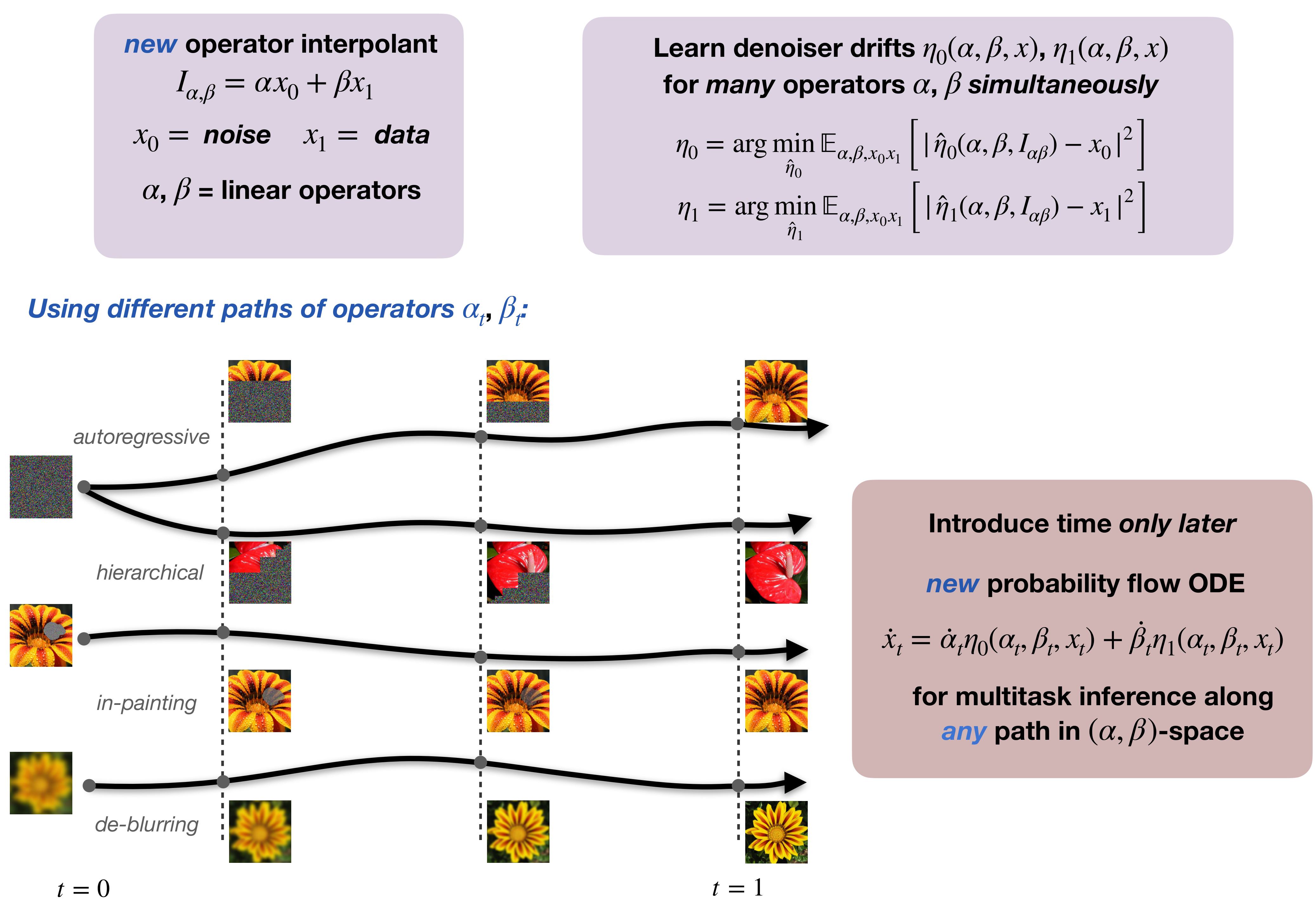
New operator interpolant
$$ \begin{align*} I_{\alpha,\beta}(x_0, x_1) = \alpha x_0 + \beta x_1,
\end{align*} $$ where $x_0 \sim$ noise, $x_1\sim$ data distribution
and $\alpha,\beta$ are linear operator.
Associated with this interpolant we introduce:
Denoiser drifts:
$$ \begin{align*} \eta_0(\alpha,\beta,x) = \mathop{\mathrm{arg
min}}\limits_{\hat \eta_0} \mathbb{E}_{x_0,x_1,\alpha,\beta}\big[|\hat
\eta_0(\alpha,\beta,I_{\alpha,\beta})- x_0|^2\big], \\
\eta_1(\alpha,\beta,x) = \mathop{\mathrm{arg min}}\limits_{\hat
\eta_1} \mathbb{E}_{x_0,x_1,\alpha,\beta}\big[|\hat
\eta_1(\alpha,\beta,I_{\alpha,\beta})- x_1|^2] \end{align*} $$
These drifts can be used to perform inference along any path in
$(\alpha,\beta)$-space using:
Probability flow ODE
$$ \begin{align*} \dot x_t = \dot \alpha_t
\eta_0(\alpha_t,\beta_t,x_t) + \dot \beta_t
\eta_1(\alpha_t,\beta_t,x_t), \qquad x_0 \overset{d}{=}
I_{\alpha_0,\beta_0} \end{align*} $$
SDE
$$ \begin{align*} dx_t = (\dot \alpha_t -\sigma_t^{2}
\alpha_t^{-1})\eta_0(\alpha_t,\beta_t,x_t) dt + \dot \beta_t
\eta_1(\alpha_t,\beta_t,x_t) dt + \sqrt{2} \sigma_t dW_t, \qquad x_0
\overset{d}{=} I_{\alpha_0,\beta_0}\end{align*} $$
In terms of sampling, solving the SDE or ODE is strictly equivalent,
that is, $Law(x_t)^{SDE} = Law(x_t)^{ODE}$. The only
difference lies in the numerical method employed; an Euler or an
Euler-Maruyama scheme respectively.
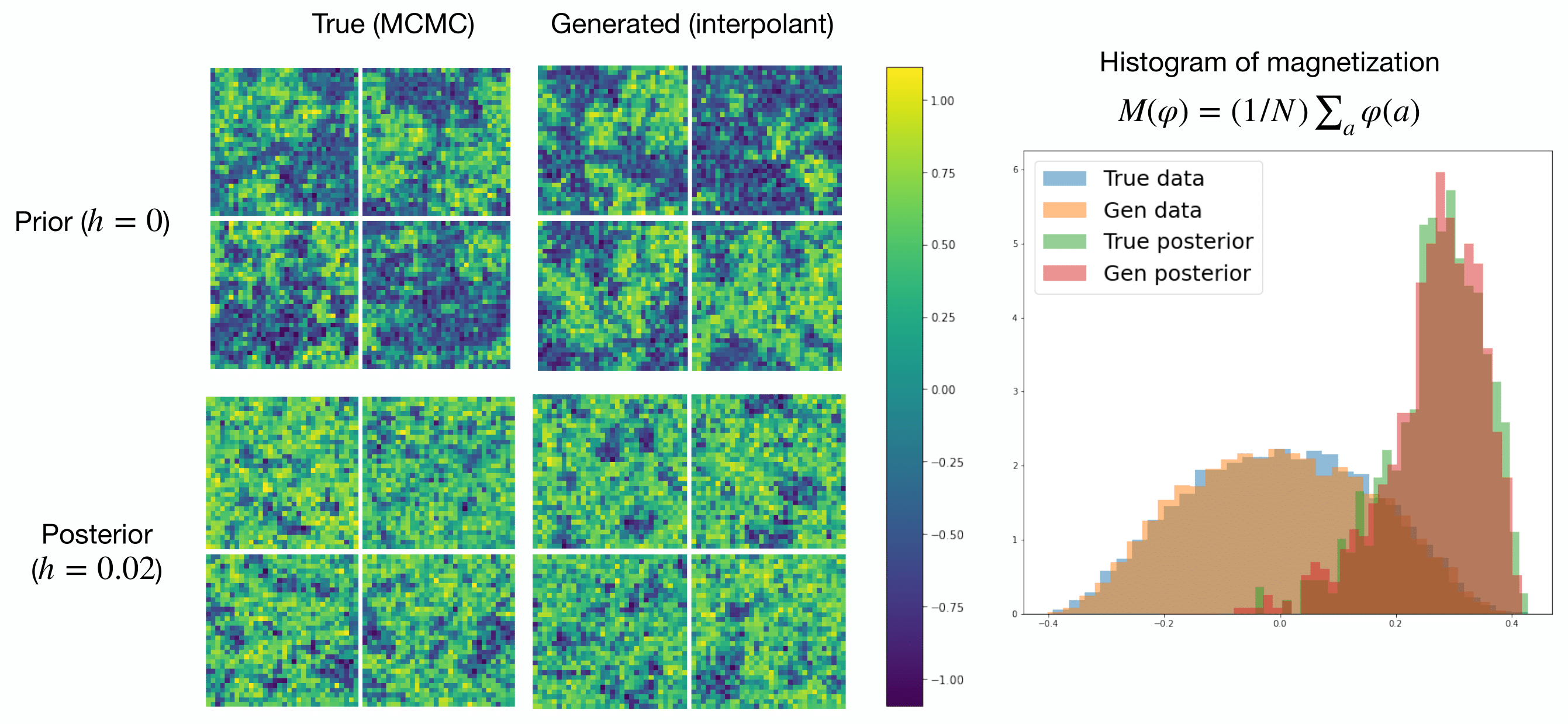
The heart of the message is that a single trained model can perform
multiple tasks of very different natures, which are uniquely
specified by the $(\alpha_t, \beta_t)_{t \in [0, 1]}$-path.